Introduction
So you want to scale your application from 10 to 10,000 users? You need to understand system design.
You want to extract services from a monolith because it is getting too large? You need to understand system design.
You want to improve the performance of a legacy project? You need to understand system design.
System design is everywhere, and I think it’s one of the things that differentiate a senior engineer from a junior.
Later, in this newsletter, we’re going to design and build complex systems. But today, let’s just get familiar with the basics.
Phase 0
When you’re starting your project, your architecture probably looks something like this:
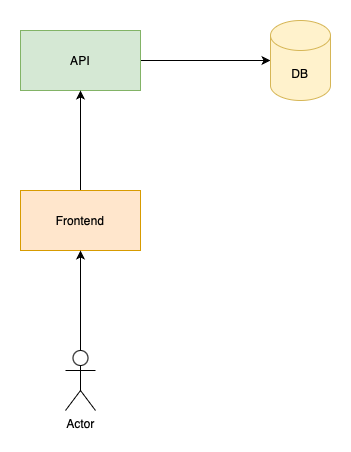
Users open a frontend that can be either a web app, a desktop app, or a mobile app (or something else) and it communicates with your backend. The backend consists of an API and a database.
It’s nice and easy, and it works well. Until you hit a certain number of users or a certain volume in activity.
Phase 1
Every project that has some long-running tasks can benefit from using a job queue and workers. A long-running task can be anything that doesn’t fit into the typical request-response lifecycle. A few examples can be:
- Resizing and storing a profile image
- Sending notifications via 3rd parties
- Generating a large report
- Executing thousands of database queries
Basically, anything that takes more time than a few hundred milliseconds. These tasks should be processed in the background so they don’t block user requests:
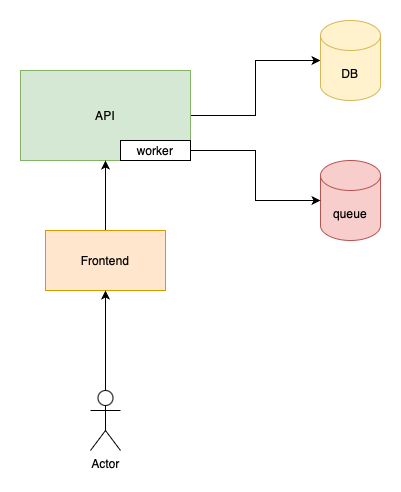
A job queue itself is often implemented using Redis. It doesn’t really matter, it can be a simple table in the database, or Kafka, or RabbitMQ.
There’s one interesting thing in the above image. The worker is not a separate component but part of the API.
This represents the simplest setup where you have:
- One server for the API
- This server starts two processes
- One for your API (for example, nginx)
- Another one for your worker process
This is the most simple setup and it has two main benefits:
- You don’t block user requests anymore with long-running tasks
- It’s very easy to set up. It doesn’t even require a new server, you just spin up a new process.
The biggest disadvantage is that your background tasks still consume the resources of the same machine that serves user requests.
Just think about if a user uploads a video on your server and the worker starts transcoding it. This process takes a long time and requires lots of resources. The user requests will be served much slower until the transcoding is in progress.
This setup works very well for small projects where you have maybe a few dozen jobs every day.
Can I ask you to subscribe to the newsletter if you’re not already a subscriber?Subscribe
Phase 2
Once you reach a certain volume, the next step is separating the API and the worker:
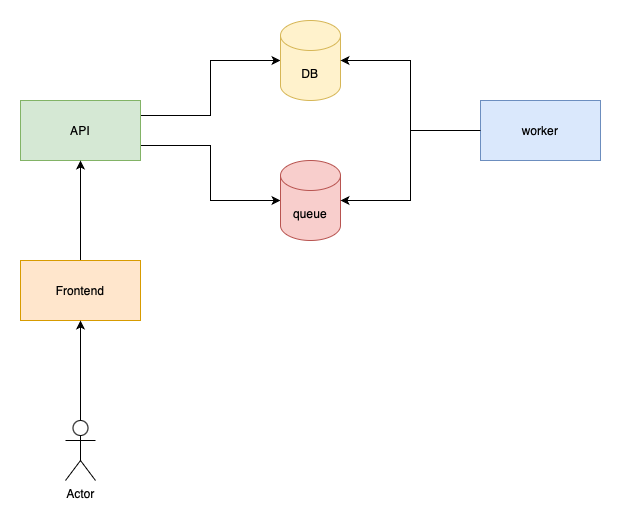
Now user requests and background jobs are processed by completely different nodes. If there’s an increase in user requests there’s no problem since the API can focus on them. If there’s an increase in background jobs then the API can still handle incoming requests while the worker processes the jobs.
So your application can handle a bigger load in general. The other benefit is that you can scale your API and your workers independently from each other.
Phase 3
Even though, processing background jobs and user requests independently is a smart idea, there’s a threshold where we need to add more nodes:
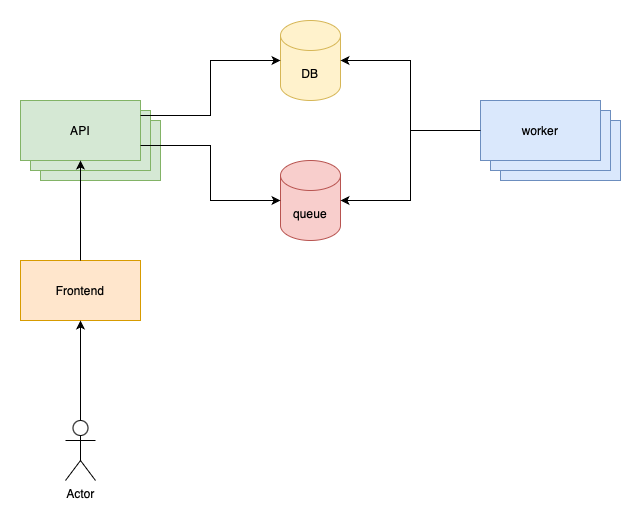
This is called horizontal scaling. Instead of increasing one node, we add more nodes and treat them as a cluster. Increasing one node is called vertical scaling.
The same computing capacity can be achieved using these two techniques. Let’s say the original API server had 2 cores and 4GB of RAM. Adding 2 more nodes, or 3xing the original one has the same effect. 6 cores and 12GB of RAM.
But still, bigger projects benefit more from horizontal scaling for the following reasons:
- Fault tolerance and redundancy. Distributing the load across multiple servers means that if one server fails, the others can still serve requests, increasing the overall system reliability.
- Elasticity. Your app can be easily scaled up or down based on demand. You can add or remove servers as needed without significant downtime.
- Load balancing. Traffic can be distributed across multiple servers, preventing any single server from becoming a bottleneck and improving performance (in a minute, we’ll talk about this one).
- Geographical distribution. Horizontal scaling allows for the deployment of servers in multiple locations, reducing latency for users in different regions. It’s probably overkill for lots of applications but worth mentioning.
Phase 4
Of course, there’s a missing component in the previous image. How should the frontend know which API server to address? The system has 3 servers with 3 different IP addresses.
A load balancer is needed to act as a single entry point to the frontend and to distribute the load evenly across the nodes:
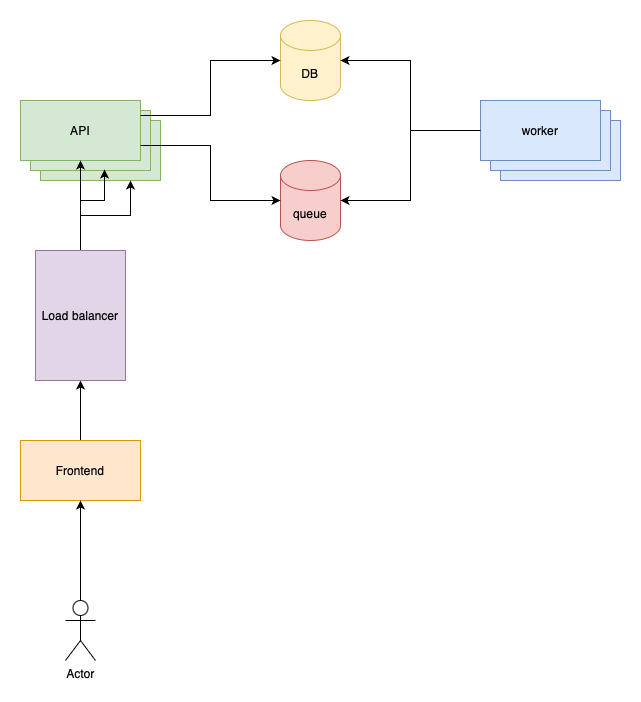
As you can see, the frontend only sends requests to the load balancer which distributes the load across the API servers.
A commonly used load balancing algorithm is round robin that looks like this:
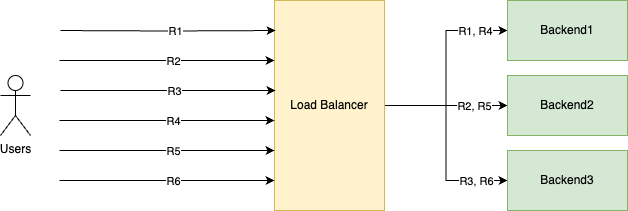
Each backend server gets an equal amount of requests in circular order:
- R1 gets handled by Backend1
- R2 gets handled by Backend2
- R3 gets handled by Backend3
- And then it starts over
- R4 gets handled by Backend1
- R5 gets handled by Backend2
- R6 gets handled by Backend3
A load balancer is a simple web server that accepts HTTP requests and sends them to other servers. There are a number of ways you can implement one:
- nginx
- haproxy
- traefik
- Managed load balancers offered by cloud providers
The most simple implementation in nginx looks like this:
user www-data;
events {}
http {
upstream backend {
server backend1.example.com;
server backend2.example.com;
server backend3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}It accepts requests on port 80 and forwards everything to the “backend” upstream. An upstream is a group of servers as you can see. By default, this simple configuration will run a round-robin load balancer across three servers.
If you like the post so far, it’d be a huge help for me if you share it!
Phase 5
Whenever you decide to horizontally scale your application local state should be removed. Imagine if the application accepts file uploads from users. If the system runs on multiple servers, the following can happen:
- User A uploads
1.pngto/storage/app/public/1.pngon Server 1. - User B wants to download the image but his request gets served by Server 2. There’s no
/storage/app/public/1.pngon Server 2 because User A uploaded it onto Server 1.
So local state means anything stored on the filesystem or in memory. Some other examples of local states:
- Databases such as MySQL. MySQL does not just use state, it is the state itself. So you cannot just run a MySQL container on a random node or in a replicated way. Being replicated means that, for example, 4 containers are running at the same time on multiple hosts. This is what we want to do with stateless services but not with a database.
- Redis also means state. The only difference is that it uses memory (but it also persists data on the SSD).
- Local storage such as files.
- File-based sessions
- File- or memory-based caches
.envfiles (kind of)
This is why AWS S3 and other object storages gained so much popularity in recent years. They offer decentralized storage:
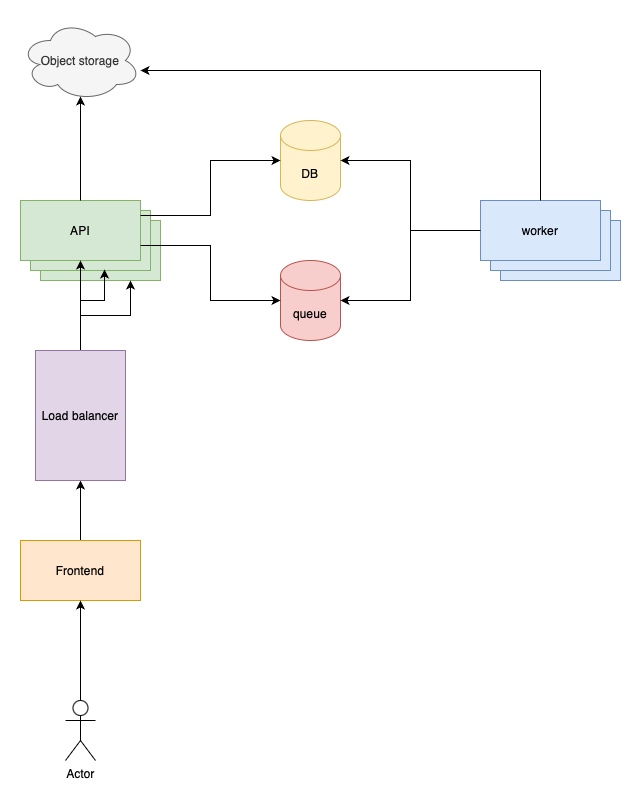
Phase 6
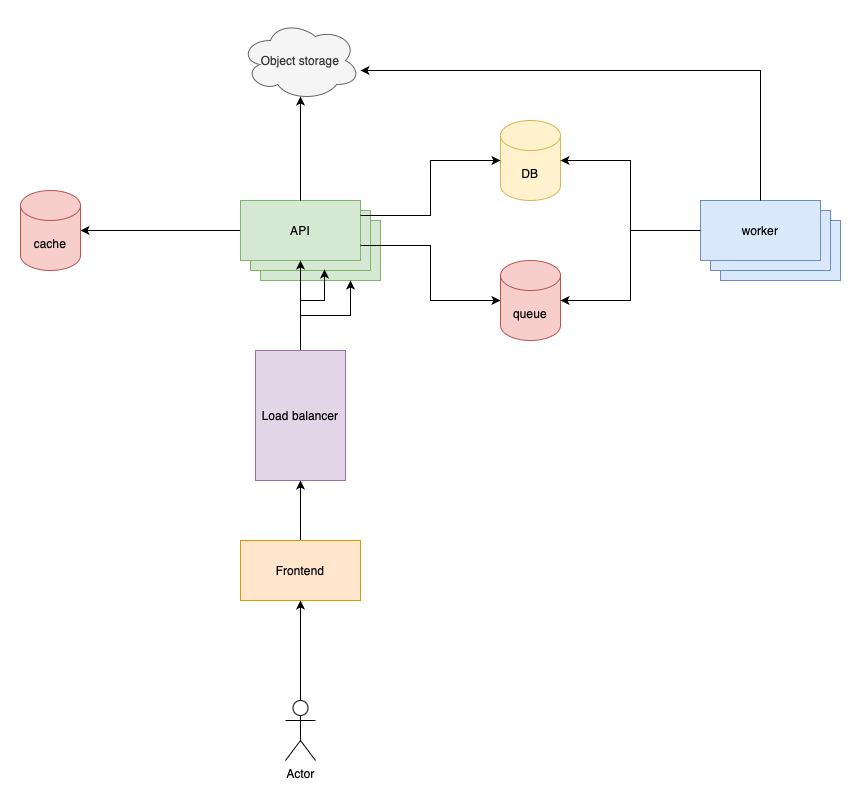
At that point, if the application has multiple servers, workers, and a load balancer, it probably has enough traffic to introduce caches.
Caching could be a whole series on its own. In this post, I’ll introduce (probably) the simplest strategy which is lazy-loading or cache aside.
In this model, the application is responsible for loading data into the cache:
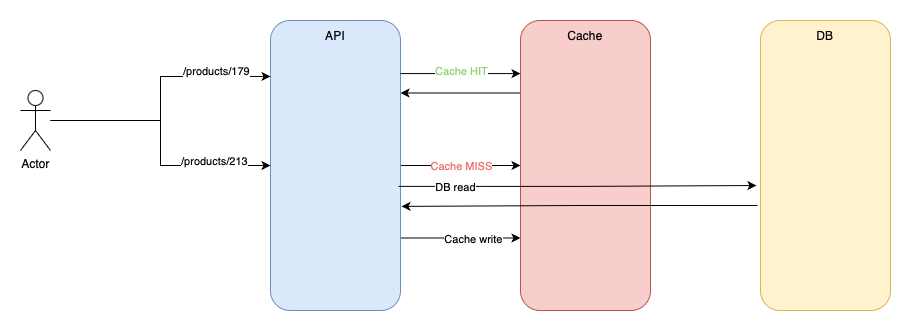
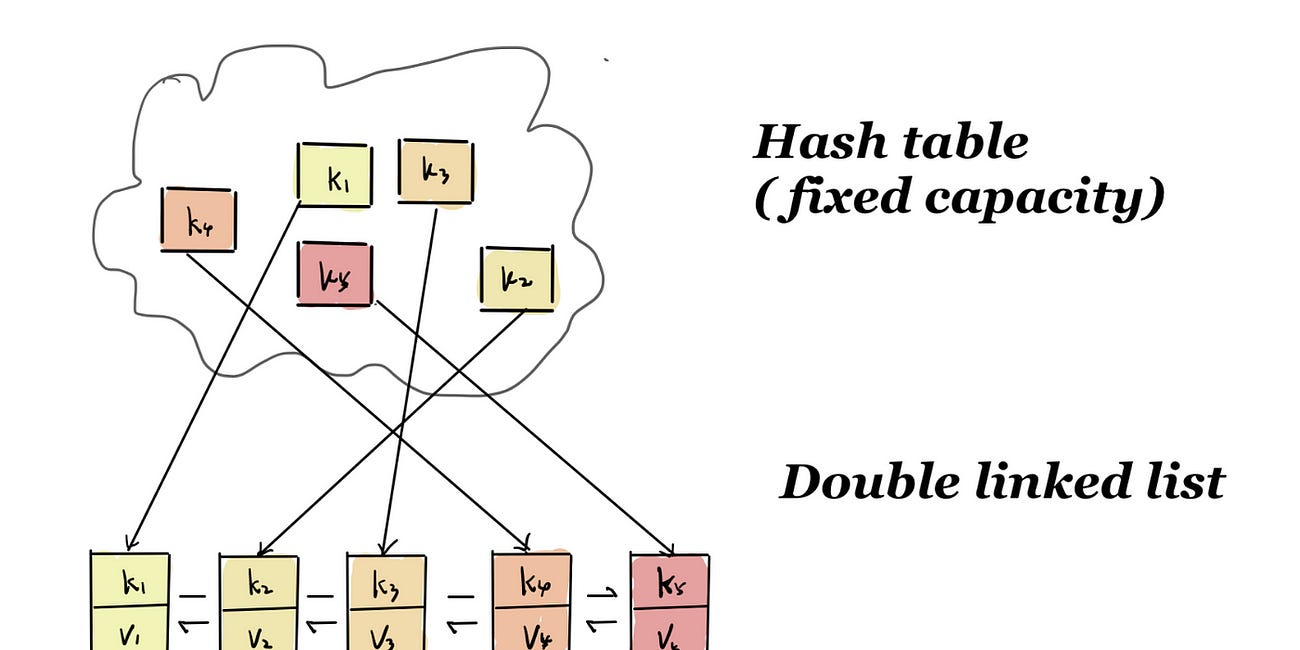
- A
/products/179request comes in. The app checks if product #179 is present in the cache. If it can be found then it’s a cache HIT so the product is served from the cache. - Another request comes in for product #213 and it’s not found in the cache. It’s a cache MISS. In this case, the app handles what should happen. Usually, the data is queried from the database and it is written back to the cache so next time product #213 can be served from the cache.
There are other cache strategies such as write-through or write-back. There are other types such as LRU caches that can be used to handle more “specialized” use cases.
Here’s a 2-part series about LRU caches:
LRU caches part I
·
Jul 16
Adding a cache to the system it looks like this:
Phase 7
Nothing has happened with the frontend yet. Usually, the API and the backend are the first bottlenecks in a system since the frontend only serves static content. However, as the JavaScript ecosystem gets more and more bloated it’s not uncommon that a simple website loads 10s of megabytes of JavaScript code. For example, the landing page of Zoom (only the landing page) loads 6MB of JavaScript code. No, I’m not talking about images or videos. Only the JS code takes 6MB.
If you add images and other assets it’s easy to load dozens of MBs of data. Your server might process it slowly if you have high traffic. But even if your server is optimized and fast, you need to send 10MB, 20MB, and 30MB of data over the network. And of course, your users have a slow 3G connection.
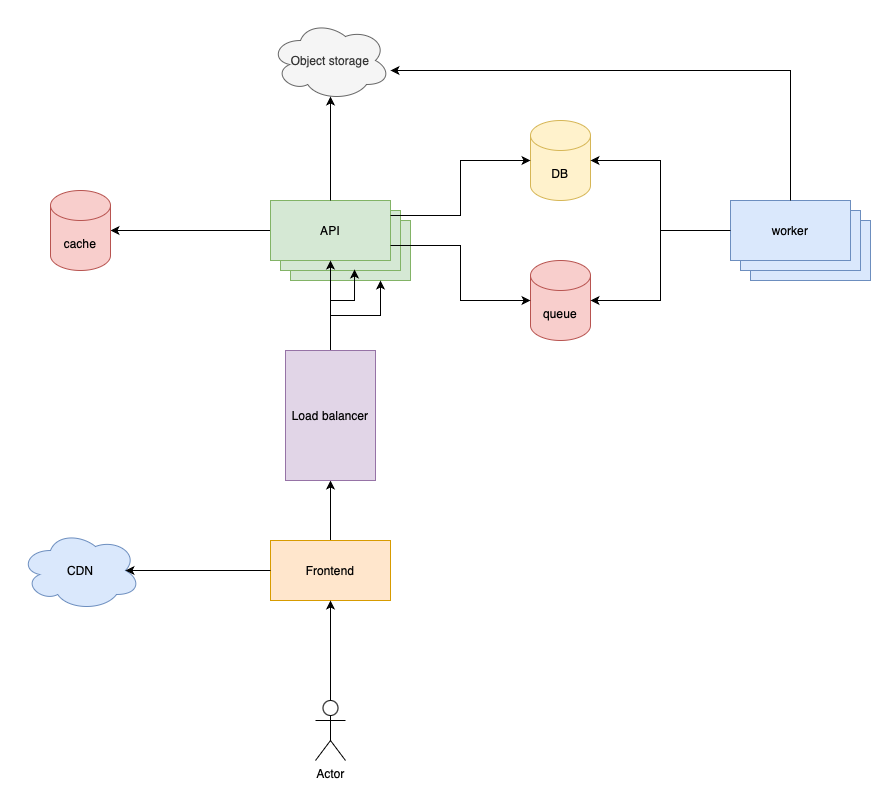
CDNs (Content Delivery Networks) can solve that problem. A CDN is just a specialized cache that stores static assets such as images, videos, CSS, and JS files. They come in the form of 3rd parties and they usually have a very big network of servers in multiple regions. They often use edge computing as well. The point is that they are closer to your users than your servers.
Serving a static file from a CDN looks very similar to a lazy-loading cache:
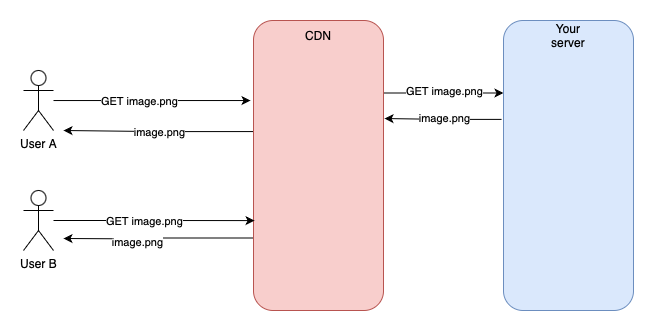
If an asset is not found on the CDN it requests it from your server and stores it. Then subsequential requests can be served using only the CDN.
POLL
Are you interested in the technical implementation of such designs? Things such as kubernetes, load balancers, etc
Yes
No
17 VOTES ·
Phase 8
At this point, if you’re not FAANG I’d say it’s a pretty good architecture that should be able to handle a large number of users. Let’s think about the remaining single point of failure:
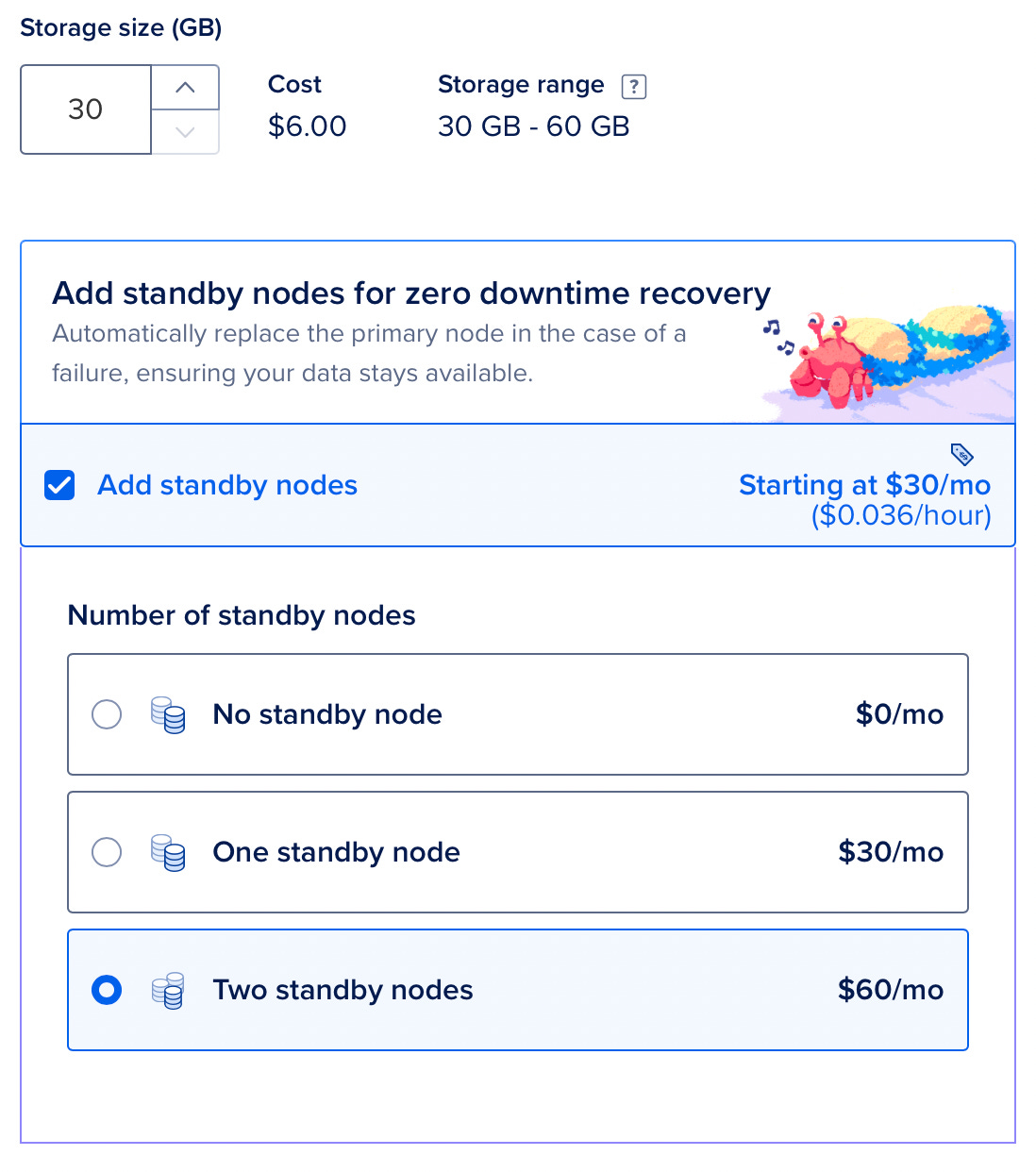
- Database. Since a database stores data in files, we cannot just spin up multiple replicas. However, most databases offer replicas. In this scenario, there’s a leader database that accepts write operations and it replicates its content to follower nodes. Followers only accept read operations. Since most applications need to serve more read operations you can add as many follower nodes as you need. If you have a managed database then it’s pretty easy to do. On DigitalOcean, which is considered a smaller cloud provider, you can have 3 nodes for $60:
- Queue. The same is true for the queue. It is state itself so we cannot just spin up multiple nodes. Most queue systems (such as Redis) offer a distributed setup as well. They can run on multiple nodes but the setup is more complicated than scaling your own API. However, Redis and other queue systems can handle an incredible amount of throughput. The database is more likely to be a bottleneck in most applications.
- Load balancer. If you look at the above image, you can think that the load balancer is a single point of failure. If the traffic is really high and it goes down the whole application becomes unavailable. It is true. However, if you use a managed LB it’s pretty easy to add multiple nodes. But even a single node can handle 10,000 concurrent connections for $12 on DigitalOcean:
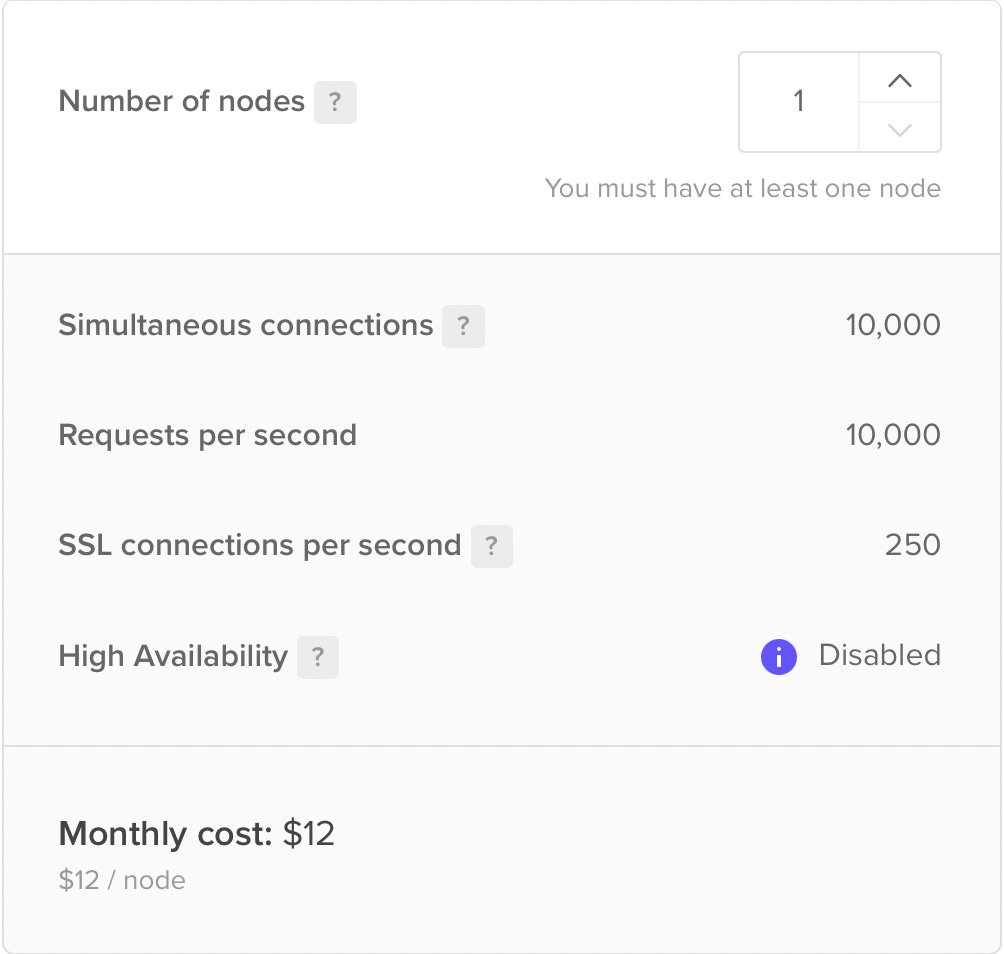
I don’t know the statistics but I guess 95% of the applications out there don’t need to handle 10,000 concurrent users 24/7. And even if it’s not enough, scaling is as easy as increasing the “Number of nodes.”
Phase 9
If your application grows really big you can go full microservice. This means that each part (feature) of your application runs on different nodes and can scale independently from each other. This can be a terrible idea if you:
- Have a small team
- Don’t know what you are doing (don’t have the required devops knowledge)
- Don’t experience problems that microservices can solve
- Or if you only do it because a Netflix engineer told it to you in a YouTube video. You’re not Netflix. I’m not Netflix. They play in a different league. They experience completely different problems so they come up with different solutions.
However, in upcoming posts, I’ll talk more about how to implement microservices.
That’s it for today. These are some of the most fundamental elements of system design. I think every software engineer should know about these, at least in theory.
Source: https://computersciencesimplified.substack.com/p/system-design-101